Introduction: Digitizing Historical Texts
The digitization of historical texts is one of the central and at the same time most demanding tasks in the Digital Humanities. The path from a physical document to a machine-readable digital version involves a series of coordinated steps: scanning the pages, performing OCR (Optical Character Recognition), correcting errors, normalizing historical spellings, and processing the text at the word level (e.g., tokenization or lemmatization) before it can be used for further analysis. The goal of this pipeline is to enable distant reading – an approach in which large text corpora are analyzed automatically without researchers having to manually read every page. This is essential for extensive source collections.

Many of the required steps are complicated, error-prone, and require either specialized technical knowledge or substantial resources. The digitization of historical prints is particularly challenging for several reasons:
- outdated and inconsistent spelling conventions
- print quality fluctuates
- suitable training data are rarely available As a result, source-specific adjustments often have to be developed.
Objective of the Study
Given these challenges, Large Language Models (LLMs) are coming into focus as a flexible alternative. They are optimized for processing natural language and could supplement or replace classical, often rigid methods and simplify the entire process.
My master’s thesis examines the extent to which this theoretical potential can actually be used under realistic conditions.
Three core tasks were investigated:
- OCR analysis: extracting text directly from page scans
- Orthographic normalization of historical texts: modernizing and unifying outdated or inconsistent spellings
- Named Entity Recognition (NER): identifying personal names and place names in the text
To ensure that the experiments reflected realistic conditions in the humanities, two strict constraints were imposed:
- All tasks had to be solved solely through prompt engineering, i.e., by optimizing the instructions given to the model rather than training or fine-tuning it.
- Only small open-source models that run on standard consumer hardware were used, typically up to about 10–12 billion parameters.
This setup reflects the practical limitations common in many humanities research environments.
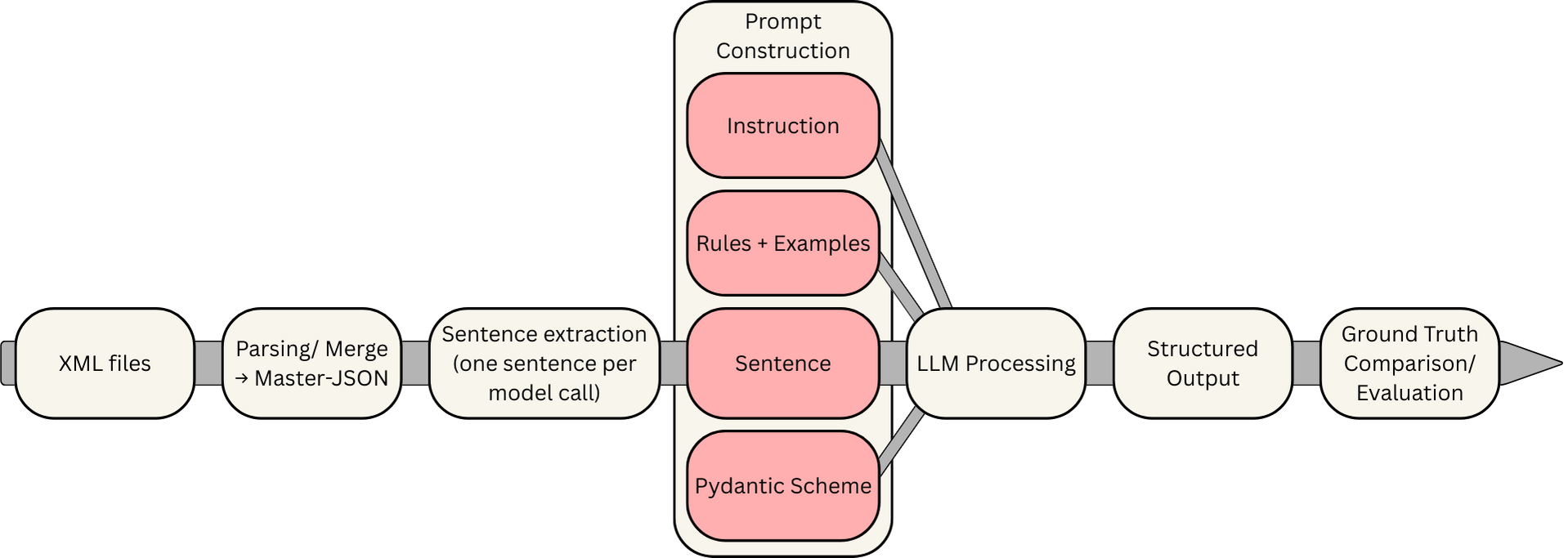
Methodology
The travel journal of Carl Peter Thunberg from the German Text Archive (DTA) served as the dataset. The source is available at several levels of annotation, which is important because it allows for realistic simulations of the individual tasks: scans plain text files XML files with lemmas, POS tags, and NER annotations
This structure enabled precise comparisons with ground truth data. To control the experiments, a master JSON file was created containing both the model inputs and the reference data for evaluation.

After testing several lightweight models, the following proved most reliable:
- Gemma 3 (12B) – for language tasks
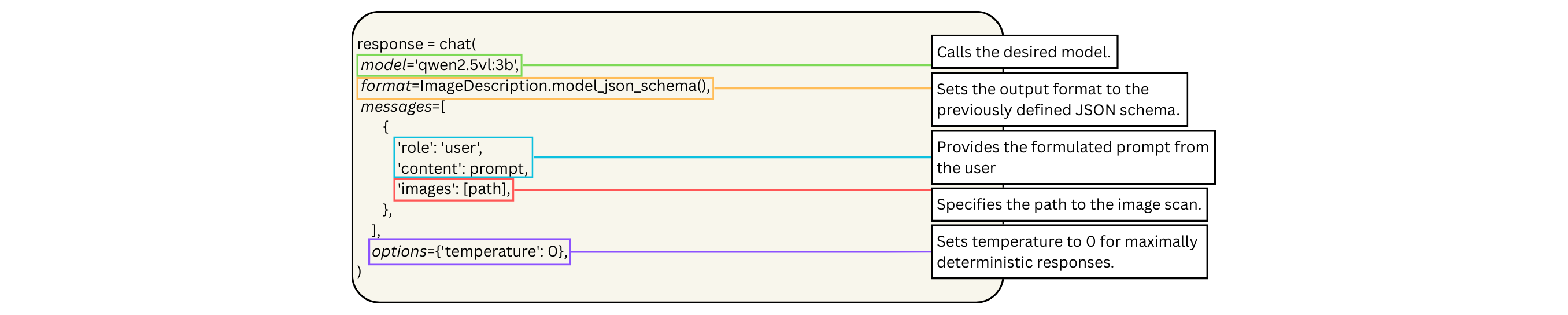
- Gwen 2.5-VL (3B) – vision model for OCR-like tasks Both models ran locally through Ollama and were automated using their Python library. A central methodological component was the strict control of output formats with Pydantic, which ensured that the LLMs produced consistent, machine-readable JSON outputs. Since small models can process only a limited number of tokens at a time, the corpus was processed sentence by sentence. In total, 6,058 model requests were required to process the entire text.
Experiment 1: Orthographic Normalization
Objective: Convert historical spellings into modern German without altering the content. This is necessary because modern NLP tools often struggle with unknown spellings and inconsistent orthography.
The model received explicit rules:
- modernize only spelling and typography
- no synonyms or paraphrasing
- do not change proper names Examples from a second report by the author were provided to clarify the task.

Results
Positive
- followed basic rules well
- correctly modernized outdated characters
- sentence structure and word choice remained largely intact low error rate
Negative
- inconsistent decisions (context loss due to sentence-wise processing)
- unknown terms sometimes overinterpreted
- occasional unnecessary changes despite clear rules
Conclusion
Under these conditions, LLM-based normalization is not useful. Rule-based tools remain:
- faster
- more consistent
- easier to control
To achieve meaningful results with LLMs, it would be necessary to provide at least some form of explicit rule set in addition to the model prompts.
Experiment 2: OCR Analysis with a Vision LLM
Objective: convert historical book pages directly into machine-readable text without classical OCR.
Originally, the workflow was meant to include both scan and OCR output so the model could correct the existing analysis. Small models, however, failed to process both inputs meaningfully. Therefore, only scans were used.
Ten pages with different layouts were tested.
Results
Pro
- some pages recognized almost flawlessly
- text extraction possible without training
- low computational requirements
- very fast processing
Contra complex layouts caused complete failure unwanted orthographic modernization model was maxed out by the task, allowing only very short prompts

Conclusion
Vision LLMs show potential but are: not reliable enough in this setup overwhelmed by complex layouts Larger models or stronger hardware would likely perform much better.
Experiment 3: Named Entity Recognition (NER)
Objective: Detect all personal and place names. Identifying persons and place names is often the easiest way to gain an understanding of a text’s content without the need for full annotation. This task is challenging due to historical names, varying spellings, and ambiguous context.
NER is crucial for:
- databases
- knowledge graphs
- geographic analyses
- network analyses of historical actors
Because combined extraction of persons and places performed poorly, two separate runs were executed. Rules were precisely defined, with example cases provided to guide the model’s behavior:
- mark only personal names / only place names
- ignore titles, professions, roles
- ignore general terms The evaluation was performed by comparing the model outputs with the reference data from the master JSON file, measuring hits, missing entries, and false positives.

Results
Pro
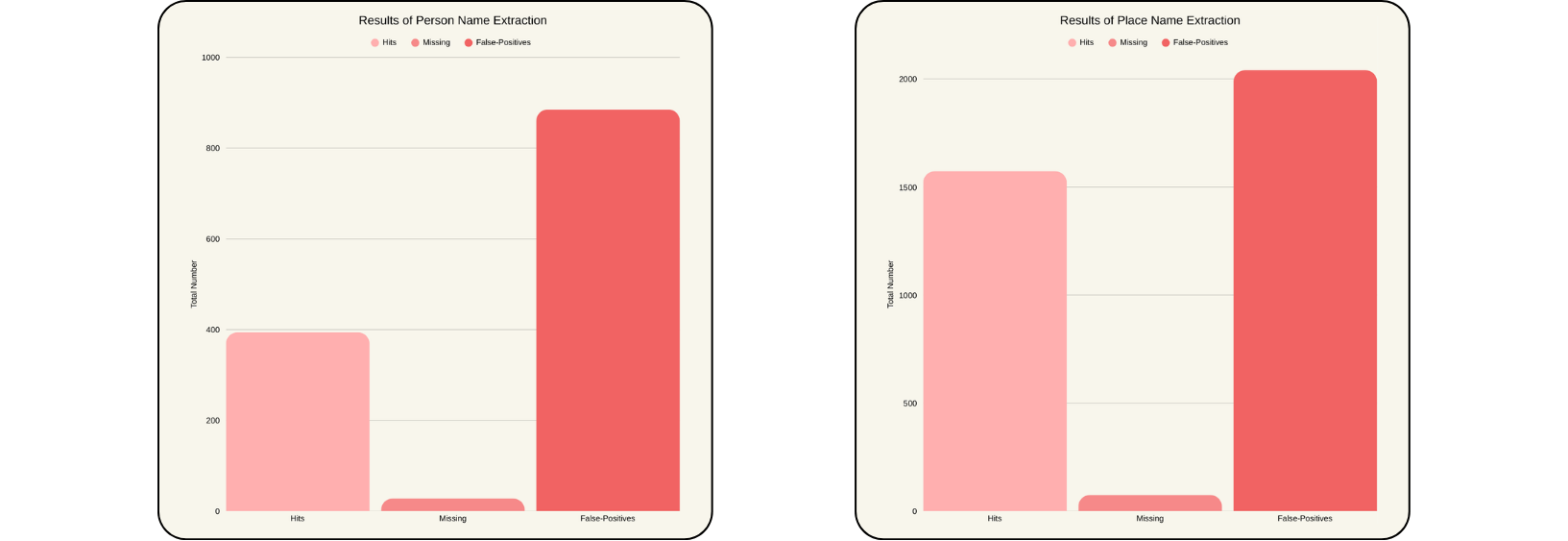
- very high recall: over 93% of actual names found
Contra
- extremely high number of false positives -> personal names: 885 incorrect vs. 422 correct
- systematic misinterpretations -> place names: Japanese, town, island → falsely treated as proper names -> personal names: king, emperor, governor → treated as valid persons
- occasional extreme outliers (hundreds of hallucinated names)
Conclusion
LLM-based NER is not practical under these conditions. Classical tools (e.g., spaCy) remain:
- faster
- more consistent
- far easier to control
Overall Result
The thesis arrives at a clear but sobering conclusion:
Lightweight LLMs can contribute to the analysis of historical texts, but under realistic conditions they are neither reliable nor efficient enough to replace classical methods.
1. Main Problem: Unreliability and Inefficiency
- high variance
- partly arbitrary decisions
- prompt engineering does not replace training and is not less complex
- problems are shifted, not solved
The usefulness of LLMs must be considered carefully. More modern tools are not always better. The normalization of historical texts with LLMs takes significantly longer, requires more computational resources, and ultimately does not outperform traditional rule-based normalization tools available online.
2. Resource Limitations of Small Models
- actual token limits often unclear
- vision LLMs break easily when tasks become slightly more complex
Outlook: Where Does the Potential Lie?
Despite their limitations, LLMs offer promising perspectives:
Tool Integration Format validation tools such as Pydantic greatly improve stability.
Specialized Agents Models, such as Qwen2.5-VL, show potential in specific areas, including image processing and format conversion.
Better Accessibility There is a strong need for graphical interfaces so that researchers can use LLM workflows without deep technical knowledge.
TL;DR
LLMs show potential for certain tasks in the Digital Humanities. Under realistic conditions, however, they remain unreliable, inconsistent, and inefficient; classical tools continue to be indispensable. LLMs are most effective when combined with structured tools and clearly defined output formats (e.g., Pydantic).